New o1 model can solve complex tasks due to a new processing step before answering.
See full article...
See full article...
None of that implies any reasoning. It merely chops up the question according to a (likely) fixed algorithm defining the possible steps it can take. With some smart programming that kind of thing could be written in almost any language in a deterministic manner.I had to try it to see how it tick'd.
GPT-4o1 resisted being "corrected", too.
View attachment 90251
Also I threw it a "simple" math question that all the other GPT's failed at because of step-bungling.
This time, it didn't bungle the steps, and apparently figured out a different way to do it than I would have done.
View attachment 90252
View attachment 90254
In order for a human to learn to not do something it doesn't need to re-learn literally everything it has ever experienced in life. Algorithms do. Algorithms do not think or have anything close to thinking. It just predicts things. The same way you can draw a line across data points and predict values that aren't there. The dataset and complexity of what it's doing has just increased.
I think the very word is bullshit.Or at least I presume we’re in agreement that humans are conscious beings
How exactly is human reasoning functionally different?Pattern matching probabilistic output machine can't "reason" or "think" and it sounds suspiciously like they are pretty much just automating the prompt engineering garbage that people go through to get an improved response.
"Spends time thinking" means running it again but saying "this time work harder"
150 Billion....
Agreed, but for many things LLMs are still very much limited, at least without having access to research models.I think one of the biggest problems with anthropomorphizing LLMs is the fact that we judge them by things that are trivial to humans, but make them seem dumb (strawberry rs that have been toted to death). Clearly the value of a new tool is not in the stuff it cannot do, but in the things it can do. Instead of focusing on performing human tasks that require human intelligence, focus should be placed on the things that an LLM is already doing 10x better than humans. They don't offer human intelligence, nor might they ever, although they offer an orthogonal kind of intelligence that can complement ours.
Humans have native system 2. LLMs are trying to emulate system 2 using only system 1 and brute force, which is why the process is so inefficient and the results are so unreliable.How exactly is human reasoning functionally different?
In other words, a lot of promise but no practical application today. These chat bots seem to give decent search results. Google could do that 2 decades ago for much cheaper before it was enshittified. Once the VC money runs dry, the current usefulness of LLMs will be curtailed further. Why would a corporation provide value to you (a customer) instead of their shareholders?Let’s say process and compress large amounts of knowledge in an instant; summarize, categorize etc as an example. There are many, many things in development now as I’m sure you are aware of. Unfortunately many of these things seem hell bent on replicating human intelligence instead of finding a good fit for the kind of intelligence that LLMs provide today. That’s why we have a lot of cool tech demos, but not enough actual products imho.
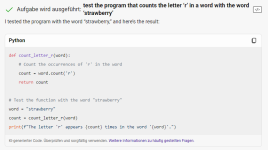
This is such a strange line of argument. Same as "It can't even do simple math!". But why should it, it is not designed for that. But there are other tools that are designed for that, namely a calculator, or a programming language. If you ask Chatgpt to write you a program to count the letter r in a word it gives you the correct implementation of that. Tada, problem solved. Guess what happens if you ask it to write you a program to add 2 and 2?man. That was such an easy example to give people when they asked me why they shouldn’t just “trust what the computer says”. I could go on and on about hallucinations, how they’d make up court cases and explain weights and probabilities and training data sets, but it wouldn’t click.
But this worked, every time:
“Look man, you can count the letters in this word for yourself. If it can’t even get that right, why would you trust it to give you correct reference information?”
If it can actually do it now I’m gonna need to find a different example.
The point is exactly that it isn't designed for "general intelligence". The value of "ask it to count the Rs" is not as a benchmark, it's as a demonstration to people who see LLM outputs and assume that it's thinking like a person. The fact that it can answer questions about quantum physics but can't count letters to the level a small child is a great "oh, this does not work the way I assumed it did" moment, which leads towards a better understanding of the strengths and limitations of LLMs. Same way that the value of demonstrating to people their own biases is not to try and show that they're stupid, it's to make them realize that their instincts are flawed.This is such a strange line of argument. Same as "It can't even do simple math!". But why should it, it is not designed for that. But there are other tools that are designed for that, namely a calculator, or a programming language. If you ask Chatgpt to write you a program to count the letter r in a word it gives you the correct implementation of that. Tada, problem solved. Guess what happens if you ask it to write you a program to add 2 and 2?

Mine still tells me 2. And I told it you’re an LLM with tokenization issues, take a closer look, still 2. I told it to spell it out. Still 2. Finally I gave it instructions to output 1 for R and 0 for not R, and the sum the total. It wrote a python script and finally got it right lol
https://chatgpt.com/share/66e36d3a-1c98-8006-b917-fb983628fe46


are you insane? that's the exact area where you necessarily need to be perfect. the quality of production code is assured by verification. if you are even the tiniest bit unsure whether your verification makes production code adhere to the requirements then your verification is useless. you have some leeway in against how many cases you verify to ensure requirements are met but each singular test have to be accurate. with ai you don't even know if the test is verifying what it supposed to verify. this is fine if you are working with some insignificant project, say flappy bird mobile game, but not for anything more serious.Programming is also an area where you don't necessarily need it to be perfect. I'm thinking in terms of testing things out and not production level coding.
This is such a strange line of argument
Three r's in bookkeeper. It's sure.

Some college students choose to plagiarize entire papers or look up test answers online because it's easier, too. I wouldn't call that "superior".There's the very best kind of evidence: people choosing to use it instead of doing the work themselves. Surely if, for example, it made their lives harder rather than easier, they would not, so very very consistently, continue making this choice.
OpenAI demos "o1" correctly counting the number of Rs in the word "strawberry."
Doing things right in the first place? Things are done as cheaply as possible in the first place and always will be. Up to now that's meant hiring entry-level employees to do first draft work and then having that edited by one or more layers of supervisors. No one's going to pay to get the first draft perfect or even very good. If LLMs can do it cheaper and even close to as good, they'll take over.
People want to use these tools—ARE using these tools—to write production code. That code frequently contains flaws. This isn't just like computer security. This is computer security.This isn't anything at all like computer security. Or nuclear weapons, or rocket science. This is business writing. Doing it badly isn't that big a deal.
Reuters also said in July on that "Strawberry has similarities to a method developed at Stanford in 2022 called "Self-Taught Reasoner” or “STaR”, one of the sources with knowledge of the matter said." So the name may have had something to do with that (STRawberry), even if Noam recalls it as a random choice. I don't know for sure.lol, in the "believe it or not" part, I definitely choose "not".
For people who don't click on tweets:
View attachment 90262
I keep seeing this statement that LLMs are good at summarizing.Let’s say process and compress large amounts of knowledge in an instant; summarize, categorize etc as an example. There are many, many things in development now as I’m sure you are aware of. Unfortunately many of these things seem hell bent on replicating human intelligence instead of finding a good fit for the kind of intelligence that LLMs provide today. That’s why we have a lot of cool tech demos, but not enough actual products imho.
In many domains, I'd consider "making up bullshit" a more severe error than making grammatical or math mistakes, or getting questions wrong but being open to correction when challenged.I explicitly demanded analysis of the severity of the errors in the original post. There are loads of tasks for which AI already makes fewer, less consequential errors. And AI is likely to improve with further development.
Except they aren't good at that. And yes, there are many things in development. There always are. LLMs/AIs have been just a few weeks away from a major breakthrough for the past two years. Just like someday, we're going to find a real use for the blockchain.Let’s say process and compress large amounts of knowledge in an instant; summarize, categorize etc as an example. There are many, many things in development now as I’m sure you are aware of. Unfortunately many of these things seem hell bent on replicating human intelligence instead of finding a good fit for the kind of intelligence that LLMs provide today. That’s why we have a lot of cool tech demos, but not enough actual products imho.
So let me get this straight...
THIS is the cutting edge of the AIgrift"industry"?
How many jobs, or college professors, actually want a 10-page paper on the Babylonian economy? This is part of the problem with LLMs. Undergrads aren't given papers to write, or sorting algorithms to code, or whatever else it is to do because their professors are dying to read their insights, or see the new genius way they've implemented bubble sort.Doing a first draft of a 10-page paper on the Babylonian economy. That draft is going to need human editing and fact-checking, but the amount of work required to create the finished paper will be much lower than if a person researched and wrote the entire thing from scratch.
For further information on this consult any college student or professor.
It seems pretty likely that first drafts of most types of academic and commercial writing are going to be done by AI in the relatively near future.
Whether that represents a 10x improvement is up to you, but it's going to disrupt a whole lot of jobs.
Yes, that's the same sort of thing that we were told about the last several generations of LLMs. This one can pass the bar exam! This one can get an amazing result on the SAT! This one can pass the MCAT! And all of those claims turned out to be less than true, in the sense that they could pass certain specific exams, because those exams were in their input data sets. But this is the LLM that's actually going to live up to the hype?The important advancement in what GPT-4o1 can do is solve code and math and PhD science questions at the level of top experts. As demonstrated by its performance on AIME, IOI, Codeforces, and GPQA Diamond. This improvement in reasoning ability applies to other domains (ie any sort of reasoning or logic problem).
Yes, that's the same sort of thing that we were told about the last several generations of LLMs. This one can pass the bar exam! This one can get an amazing result on the SAT! This one can pass the MCAT! And all of those claims turned out to be less than true, in the sense that they could pass certain specific exams, because those exams were in their input data sets. But this is the LLM that's actually going to live up to the hype?
Your point is only valid if you have man hours to spend and the budget that goes with that. If you give the human and the LLM each ten seconds to summarize a 300 page document? Or to do a sentiment analysis of 100000 posts about your brand?Except they aren't good at that. And yes, there are many things in development. There always are. LLMs/AIs have been just a few weeks away from a major breakthrough for the past two years. Just like someday, we're going to find a real use for the blockchain.
Don't know. Do you care about the results? If you don't care that the summary is accurate, or are OK with the sentiment analysis not being correct, then go with an LLM. As always, a lot of what's driving LLM interest is "we don't want to have to pay real people to do X. Maybe this thing can do X just well enough to replace a person." Or do it well enough for long enough for me to get promoted, and we forget what the weaknesses of the new solution is.Your point is only valid if you have man hours to spend and the budget that goes with that. If you give the human and the LLM each ten seconds to summarize a 300 page document? Or to do a sentiment analysis of 100000 posts about your brand?
Again, depends on your use case. If you have lots of time to spend and mistakes are costly, then yes humans are the way to go. If it needs to be quick, cheap and right most of the time then LLMs are way superior.I keep seeing this statement that LLMs are good at summarizing.
The article describes how this new cutting-edge LLM confabulated an answer to a crossword puzzle clue that it was never given. It added new "information" to the output entirely unrelated to the input it was asked to deal with. For a crossword puzzle maybe that's not a big deal, but for a summary of an article? If I can't trust the summary didn't introduce new "information", what good is it?
I don't want to need to check every single fact in a summary to the article or paper or law or court case or test log or whatever it's referencing. If I need to confirm every part of the summary is accurate to the article, manually, every time no matter how many times I've had the LLM do this task for me without error, it doesn't seem very useful.
And that's ignoring the other problem of what it might leave out. Maybe it left out pertinent information. Maybe I'd be much better off getting familiar with the subject matter myself. A lawmaker might rely on summaries of bills written by their support staff, but they've hand-selected that support staff. They trust that their support staff shares their values or at least can know to compensate and ask questions for any particular biases. At the very least they can trust that their staff won't make up bullshit that isn't in the bill at all, or leave out key data. An LLM has no values, can't be trusted to include all information that you'd consider key, and can't be trusted not to make up bullshit.
How does this new model do on variations of the cabbage boat goat problem? Because someone was giving example outputs for those in another AI thread, and the older models were hilariously bad.The prior models had extreme difficulty generalizing reasoning to new facts, and even more difficulty when the reasoning was on a problem adjacent to problem in the training but with a variation (Ie the goat cabbage boat problem).
People skim documents, its akin to a quick and dirty summary. It’s not a binary thing, most use cases fall on a scale of accurate vs fast.Don't know. Do you care about the results? If you don't care that the summary is accurate, or are OK with the sentiment analysis not being correct, then go with an LLM. As always, a lot of what's driving LLM interest is "we don't want to have to pay real people to do X. Maybe this thing can do X just well enough to replace a person." Or do it well enough for long enough for me to get promoted, and we forget what the weaknesses of the new solution is.
But people are using them, and companies are selling them, for the 100% right use cases.Again, depends on your use case. If you have lots of time to spend and mistakes are costly, then yes humans are the way to go. If it needs to be quick, cheap and right most of the time then LLMs are way superior.
Lets say for instance you need to float potential issues in a document. An LLM could cross reference that document with millions of sources instantly. Sometimes it might get things wrong, but thats ok, because the cost of this is small and the upside of finding real issues is immensely valuable.
If you put the LLM in a position where it needs to be right 100% of the time, you’re bound to fail. See self driving cars for instance. LLMs are for the 90% right and quick/cheap is good enough.
Except they aren't good at that. And yes, there are many things in development. There always are. LLMs/AIs have been just a few weeks away from a major breakthrough for the past two years. Just like someday, we're going to find a real use for the blockchain.
Skimming the document means you'll miss data sometimes. Rarely will you create new data that doesn't exist in the document by skimming. It would take an especially poorly written document or an especially incompetent reviewer to do that regularly.Have you heard of skimming a document, its something people do which is akin to a quick and dirty summary. It’s not a binary thing, most use cases fall on a scale of accurate vs fast.
It's work they need to do. They choose this tool to do it. You may not like that they choose this tool. You may not like that they choose to do this work. What's undeniable is the choice is happening, meaning THEY find it more valuable/easier than the old way of doing the task. The results, for them, are compelling. Hundreds of thousands of people are using this in their daily work, and not getting fired for it.Some college students choose to plagiarize entire papers or look up test answers online because it's easier, too. I wouldn't call that "superior".
Some professional software developers choose to blindly copy stackoverflow answers or cargo-cult larger tutorials found online. I wouldn't call that superior, either.
Whether people choose to use something out of laziness or ease of use is not a good measure of a thing's actual worth, in isolation.