New o1 model can solve complex tasks due to a new processing step before answering.
See full article...
See full article...
"I still have trouble defining 'reasoning' in terms of LLM capabilities. I’d be interested in finding a prompt which fails on current models but succeeds on strawberry that helps demonstrate the meaning of that term."

This is hilarious.I guess they get some points for being self aware with the naming at least. If anyone doesn't know the reference it's a pretty famous example of the problem with how token work:
View attachment 90214
I found it works to tell it to check its tokenization. This is from three weeks ago. Well, it sort of worked...I guess they get some points for being self aware with the naming at least. If anyone doesn't know the reference it's a pretty famous example of the problem with how token work:
View attachment 90214

I suspect he will be searching for a very long time.Simon Willison tweeted in response to a Bloomberg story about Strawberry, "I still have trouble defining 'reasoning' in terms of LLM capabilities. I’d be interested in finding a prompt which fails on current models but succeeds on strawberry that helps demonstrate the meaning of that term.
I won't be surprised if we find out there's a "data center" in India that's actually 200 guys Mechanical Turking itsounds suspiciously like they are pretty much just automating the prompt engineering garbage that people go through to get an improved response.
Not impressed. Anyone can build an AutoGPT-like solution that brute forces the model into progressively producing better outputs. I know because I built the same thing with off-the-shelf Llama 2 to stop hallucinations when indexing and reading ebooks. All you need is a GPU of your own to run inference, and you can hit it all day long for free.
https://www.hackster.io/mrmlcdelgado/pytldr-317c1d
In showing this to a colleague last week ChatGPT got strawberry = 3 r's right off the bat. I suspect that they had 'tuned' the model directly after recent coverage (aka hard coded the answer), as raspberry was still returning a count between 1 and 4.I guess they get some points for being self aware with the naming at least. If anyone doesn't know the reference it's a pretty famous example of the problem with how token work:
View attachment 90214
Just switch to Ideogram, it does work really well, not everything should be from OpenAI.They should get their ass in gear and update DALL-E. It makes the same "strawberry mistakes" as it did a year ago, while having twice as many "content restrictions" when generating images. Thanks Disney. :-/
Just try any different word at all - if it works for strawberry now they probably hard coded.man. That was such an easy example to give people when they asked me why they shouldn’t just “trust what the computer says”. I could go on and on about hallucinations, how they’d make up court cases and explain weights and probabilities and training data sets, but it wouldn’t click.
But this worked, every time:
“Look man, you can count the letters in this word for yourself. If it can’t even get that right, why would you trust it to give you correct reference information?”
If it can actually do it now I’m gonna need to find a different example.
We won't get an LLM like that because that's not how LLMs operate - it has no concept of tries or probability of accuracy.The strawberry problem is so interesting to me because it's a question that is honestly completely irrelevant to any valuable use of the tool. It (this specific output) only has to be solved for PR/marketing reasons.
Have they really gotten at the root cause, or is this just a patch that solves this particular kind of question? How can you generalize finding this mistake, and when multiple methods get different answers, how do you pick the correct one in a general way?
It seems like we might benefit from valuing the LLM to have some humility and say, "I tried these three ways and I think this answer is the most likely but also consider if it might be these other answers."
Three r's in bookkeeper. It's sure.Just try any different word at all - if it works for strawberry now they probably hard coded.
Can someone with GPT plus ask Strawberry
"how many rs are in the red fruit that is commonly used for daiquiris"
The red fruit commonly used for daiquiris is the strawberry. The word "strawberry" contains two letter "r"s. Therefore, there are 2 "r"s in the word "strawberry".
An LLM chat bot that doesn't hallucinate? Sounds too good to be true.Not impressed. Anyone can build an AutoGPT-like solution that brute forces the model into progressively producing better outputs. I know because I built the same thing with off-the-shelf Llama 2 to stop hallucinations when indexing and reading ebooks. All you need is a GPU of your own to run inference, and you can hit it all day long for free.
https://www.hackster.io/mrmlcdelgado/pytldr-317c1d
Error correcting through repetition / reproducibility should be part of the service, even if it isn’t a native aspect of the LLM part of that service.We won't get an LLM like that because that's not how LLMs operate - it has no concept of tries or probability of accuracy.
How many s are in 6 mississippis during an s storm?Now can it count how many s's in Mississippi?
I won't be surprised if we find out there's a "data center" in India that's actually 200 guys Mechanical Turking it
Just after the OpenAI o1 announcement, Hugging Face CEO Clement Delangue wrote, "Once again, an AI system is not 'thinking', it's 'processing', 'running predictions',...
Given that it's quite good at generating code that almost works, I do wonder about asking it to "write a python function to count the number of letters in a word", and then ask it to evaluate the output (or is the latter not feasible?).Three r's in bookkeeper. It's sure.
The root cause is that it isn't thinking or reasoning at all. The language-model is just a really big statistical analysis of what words get used together. It determines what words are most likely to appear, then picks randomly using the probabilities generated by the language-model. Also it looks like they haven't even installed a patch for the type of question, just hard-coded an answer for that particular question.The strawberry problem is so interesting to me because it's a question that is honestly completely irrelevant to any valuable use of the tool. It (this specific output) only has to be solved for PR/marketing reasons.
Have they really gotten at the root cause, or is this just a patch that solves this particular kind of question? How can you generalize finding this mistake, and when multiple methods get different answers, how do you pick the correct one in a general way?
It seems like we might benefit from valuing the LLM to have some humility and say, "I tried these three ways and I think this answer is the most likely but also consider if it might be these other answers."
In order for a human to learn to not do something it doesn't need to re-learn literally everything it has ever experienced in life. Algorithms do. Algorithms do not think or have anything close to thinking. It just predicts things. The same way you can draw a line across data points and predict values that aren't there. The dataset and complexity of what it's doing has just increased.I appreciate what he’s getting at, but are humans not doing such things? We can catch a ball fairly reliably before learning calculus explicitly.
The crux seems to be that it’s difficult to comprehensively itemize differences between human thinking and state of the art AI… processes(?).
IMO that difficultly goes a long way to excusing non-experts who call it “thinking.”
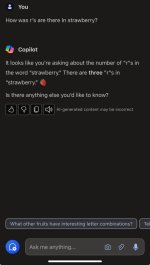
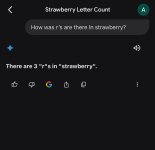
This is interesting, I see Chatgp gets it wrong but both copilot and Gemini gets it rightI guess they get some points for being self aware with the naming at least. If anyone doesn't know the reference it's a pretty famous example of the problem with how token work:
View attachment 90214

Given they train the models on social media content and this has been so widely discussed lately any new models going forward are probably going to recognize the question and respond "Three, and I see what you're doing there."The strawberry problem is so interesting to me because it's a question that is honestly completely irrelevant to any valuable use of the tool. It (this specific output) only has to be solved for PR/marketing reasons.
Have they really gotten at the root cause, or is this just a patch that solves this particular kind of question? How can you generalize finding this mistake, and when multiple methods get different answers, how do you pick the correct one in a general way?
It seems like we might benefit from valuing the LLM to have some humility and say, "I tried these three ways and I think this answer is the most likely but also consider if it might be these other answers."