
OpenAI finally unveiled its rumored "Strawberry" AI language model on Thursday, claiming significant improvements in what it calls "reasoning" and problem-solving capabilities over previous large language models (LLMs). Formally named "OpenAI o1," the model family will initially launch in two forms, o1-preview and o1-mini, available today for ChatGPT Plus and certain API users.
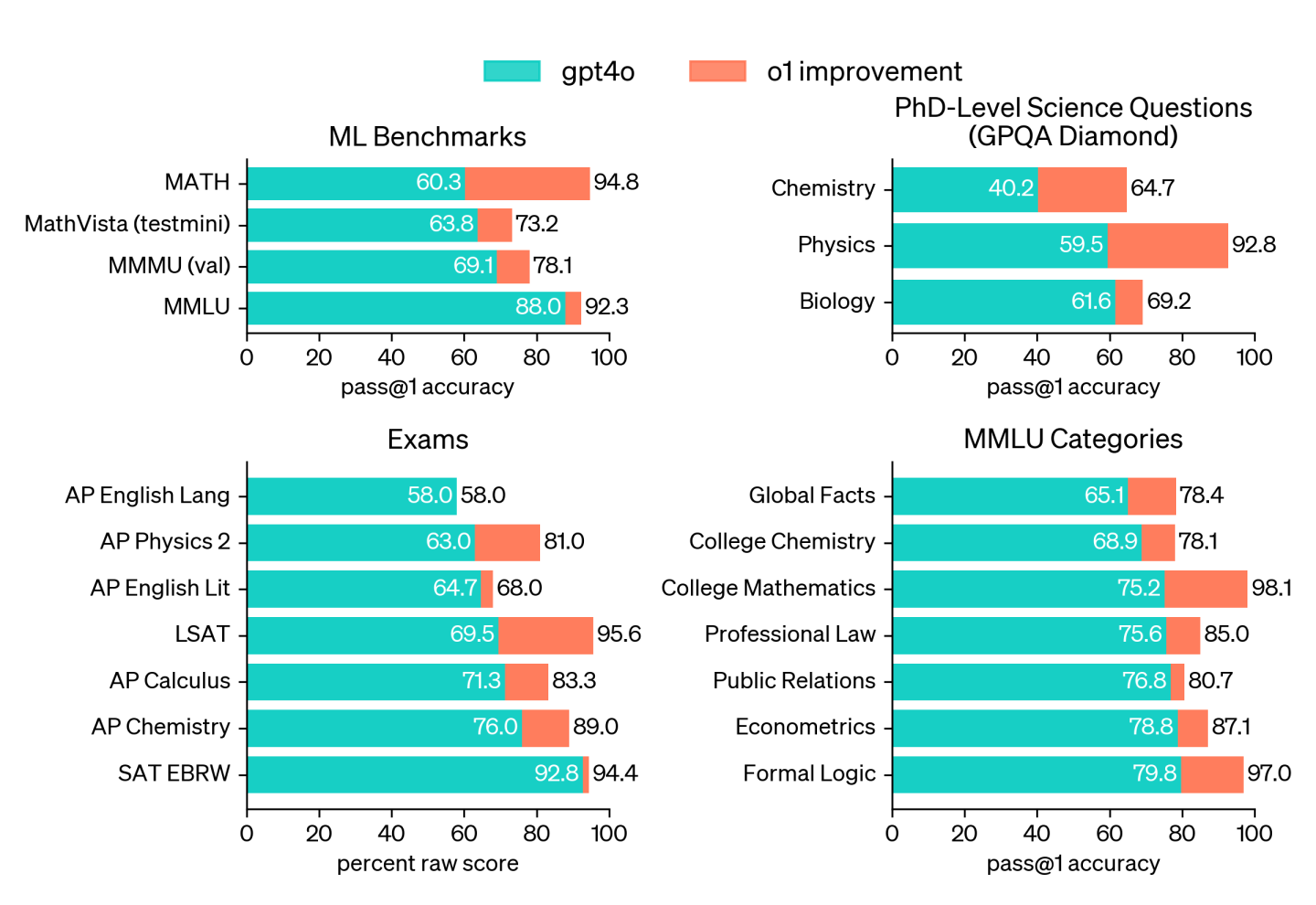
OpenAI claims that o1-preview outperforms its predecessor, GPT-4o, on multiple benchmarks, including competitive programming, mathematics, and "scientific reasoning." However, people who have used the model say it does not yet outclass GPT-4o in every metric. Other users have criticized the delay in receiving a response from the model, owing to the multi-step processing occurring behind the scenes before answering a query.
In a rare display of public hype-busting, OpenAI product manager Joanne Jang tweeted, "There's a lot of o1 hype on my feed, so I'm worried that it might be setting the wrong expectations. what o1 is: the first reasoning model that shines in really hard tasks, and it'll only get better. (I'm personally psyched about the model's potential & trajectory!) what o1 isn't (yet!): a miracle model that does everything better than previous models. you might be disappointed if this is your expectation for today's launch—but we're working to get there!"
OpenAI reports that o1-preview ranked in the 89th percentile on competitive programming questions from Codeforces. In mathematics, it scored 83 percent on a qualifying exam for the International Mathematics Olympiad, compared to GPT-4o's 13 percent. OpenAI also states, in a claim that may later be challenged as people scrutinize the benchmarks and run their own evaluations over time, o1 performs comparably to PhD students on specific tasks in physics, chemistry, and biology. The smaller o1-mini model is designed specifically for coding tasks and is priced at 80 percent less than o1-preview.





I am working with kids - and their parents - and the assumption has largely been “just ask ChatGPT, it’s an AI like in movies.” Because marketers decided to call these chatbots AI, and people know that an AI is like super smart and can do everything.
Essentially it was given blind trust. My attempts to explain why you shouldn’t do that never really worked. I’d start talking about hallucinations, or I’d bring up examples of times where someone used it professionally and it caused a problem - like those made up court cases, or referencing books that don’t exist - and the explanation didn’t help. I would try to explain the concept of a training dataset and how these models “learn” and was usually met with blank states.
So I needed a way to show that this tool is not “an AI like in movies” and it was a perfect example for that. Sometimes, once they saw it, they’d ask why it couldn’t do simple counting, and then I could get into a little more detail about how they worked.
Part of what I’m doing is trying to explain how it’s a tool that is good at some things and not at other things, but to achieve that I first have to dispel the notion that it’s good at everything.