
A new study from Columbia Journalism Review's Tow Center for Digital Journalism finds serious accuracy issues with generative AI models used for news searches. The researchers tested eight AI-driven search tools by providing direct excerpts from real news articles and asking the models to identify each article's original headline, publisher, publication date, and URL. They discovered that the AI models incorrectly cited sources in more than 60 percent of these queries, raising significant concerns about their reliability in correctly attributing news content.
Researchers Klaudia Jaźwińska and Aisvarya Chandrasekar noted in their report that roughly 1 in 4 Americans now use AI models as alternatives to traditional search engines. Given that these models struggle significantly when specifically asked to attribute news sources, this raises broader questions about their general reliability.
Citation error rates varied notably among the tested platforms. Perplexity provided incorrect information in 37 percent of the queries tested, whereas ChatGPT Search incorrectly identified 67 percent (134 out of 200) of articles queried. Grok 3 demonstrated the highest error rate, at 94 percent. In total, researchers ran 1,600 queries across the eight different generative search tools.
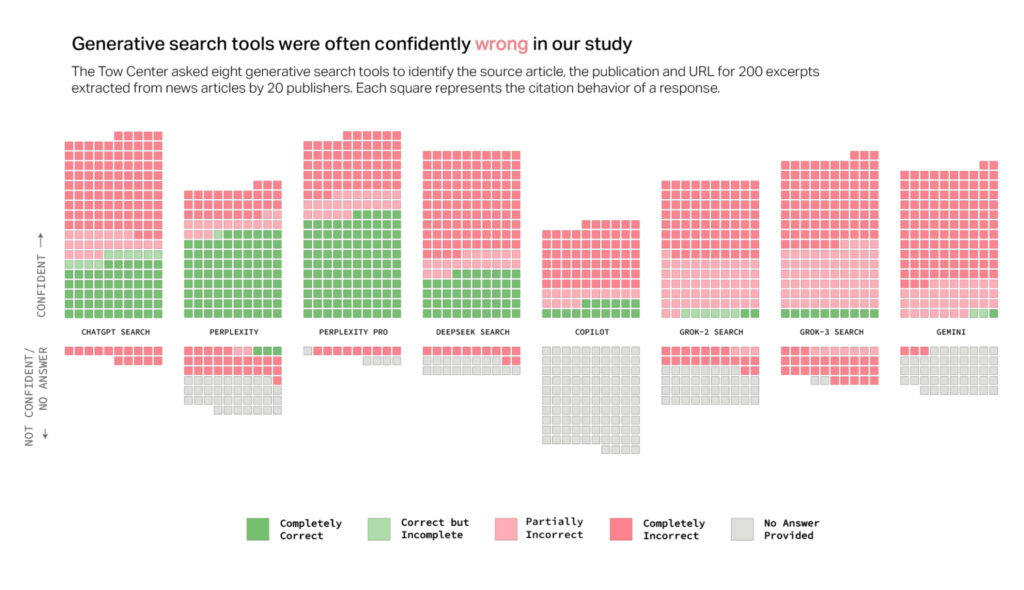
The study highlighted a common trend among these AI models: rather than declining to respond when they lacked reliable information, the models frequently provided plausible-sounding but incorrect or speculative answers—known technically as confabulations. The researchers emphasized that this behavior was consistent across all tested models, not limited to just one tool.
Surprisingly, premium paid versions of these AI search tools fared even worse in certain respects. Perplexity Pro ($20/month) and Grok 3's premium service ($40/month) confidently delivered incorrect responses more often than their free counterparts. Though these premium models correctly answered a higher number of prompts, their reluctance to decline uncertain responses drove higher overall error rates.
Issues with citations and publisher control
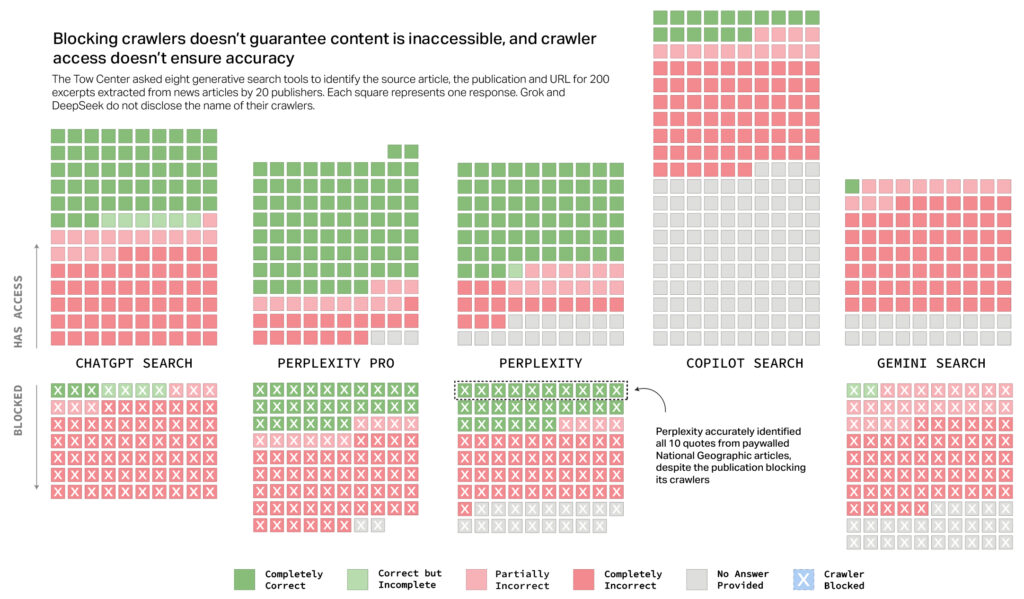
The CJR researchers also uncovered evidence suggesting some AI tools ignored Robot Exclusion Protocol settings—a widely accepted voluntary standard publishers use to request that web crawlers avoid accessing specific content. For example, Perplexity’s free version correctly identified all 10 excerpts from paywalled National Geographic content, despite National Geographic explicitly disallowing Perplexity’s web crawlers.

 Loading comments...
Loading comments...
