
On Thursday, Inception Labs released Mercury Coder, a new AI language model that uses diffusion techniques to generate text faster than conventional models. Unlike traditional models that create text word by word—such as the kind that powers ChatGPT—diffusion-based models like Mercury produce entire responses simultaneously, refining them from an initially masked state into coherent text.
Traditional large language models build text from left to right, one token at a time. They use a technique called "autoregression." Each word must wait for all previous words before appearing. Inspired by techniques from image-generation models like Stable Diffusion, DALL-E, and Midjourney, text diffusion language models like LLaDA (developed by researchers from Renmin University and Ant Group) and Mercury use a masking-based approach. These models begin with fully obscured content and gradually "denoise" the output, revealing all parts of the response at once.
While image diffusion models add continuous noise to pixel values, text diffusion models can't apply continuous noise to discrete tokens (chunks of text data). Instead, they replace tokens with special mask tokens as the text equivalent of noise. In LLaDA, the masking probability controls the noise level, with high masking representing high noise and low masking representing low noise. The diffusion process moves from high noise to low noise. Though LLaDA describes this using masking terminology and Mercury uses noise terminology, both apply a similar concept to text generation rooted in diffusion.
Much like the creation of an image synthesis model, researchers build text diffusion models by training a neural network on partially obscured data, having the model predict the most likely completion and then comparing the results with the actual answer. If the model gets it correct, connections in the neural net that led to the correct answer get reinforced. After enough examples, the model can generate outputs with high enough plausibility to be useful for tasks like coding (although, so far, they still confabulate frequently on many topics).
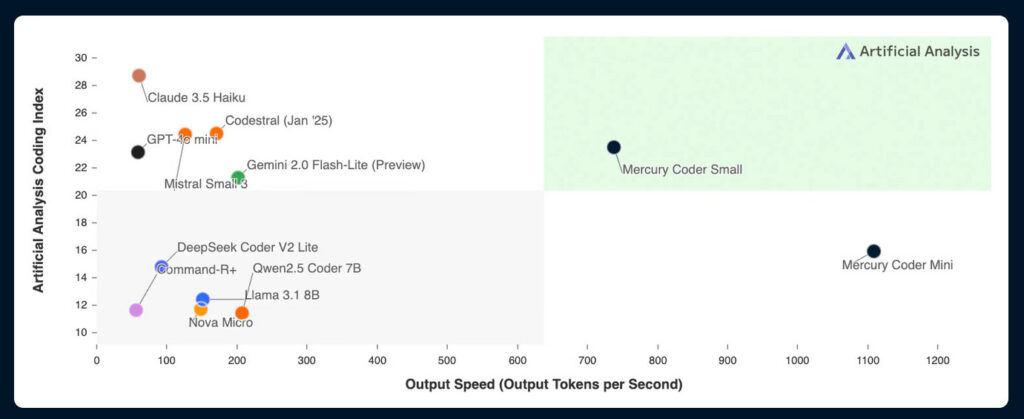
According to Inception Labs, its approach allows the model to refine outputs and address mistakes because it isn't limited to considering only previously generated text. This parallel processing enables Mercury's reported 1,000-plus tokens per second generation speed on Nvidia H100 GPUs.

 Loading comments...
Loading comments...
