
On Monday, Anthropic announced Claude 3.7 Sonnet, a new AI language model with a simulated reasoning (SR) capability called "extended thinking," allowing the system to work through problems step by step. The company also revealed Claude Code, a command line AI agent for developers currently available as a limited research preview.
Anthropic calls Claude 3.7 the first "hybrid reasoning model" on the market, giving users the option to choose between quick responses or extended, visible chain-of-thought processing similar to OpenAI's o1 and o3 series models, Google's Gemini 2.0 Flash Thinking, and DeepSeek's R1. When using Claude 3.7's API, developers can specify exactly how many tokens the model should use for thinking, up to its 128,000 token output limit.
The new model is available across all Claude subscription plans, and the extended thinking mode feature is available on all plans except the free tier. API pricing remains unchanged at $3 per million input tokens and $15 per million output tokens, with thinking tokens included in the output pricing since they are part of the context considered by the model.
In another interesting development—since Claude 3.5 Sonnet was known as something of a Goody Two-shoes in the AI world—Anthropic said that it had reduced unnecessary refusals in 3.7 Sonnet by 45 percent. In other words, 3.7 Sonnet is more likely to do what you ask without complaining about ethical boundaries, which can otherwise pop up in innocent situations when interpreted incorrectly by the neural network running under Claude's hood.
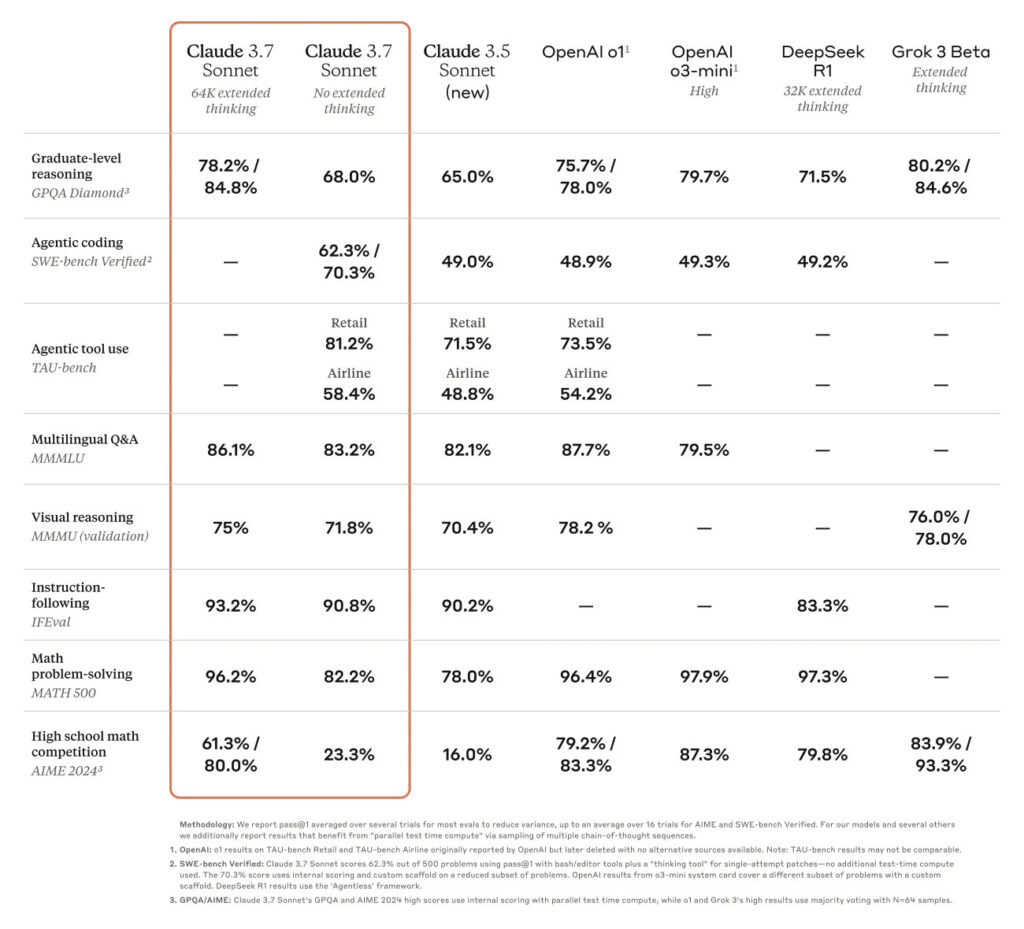
In benchmarks, Anthropic's latest model seems to hold its own and even excels in at least one category in particular: coding. Claude 3.5 Sonnet, 3.7's predecessor, was excellent at programming tasks compared to other AI models in our experience, and according to Anthropic, early testing indicates strong performance in that area. The company claims Claude 3.7 Sonnet achieved top scores on SWE-bench Verified, which evaluates how AI models handle real-world software issues, and in TAU-bench, which tests AI agents on complex tasks with user and tool interactions.

 Loading comments...
Loading comments...
