
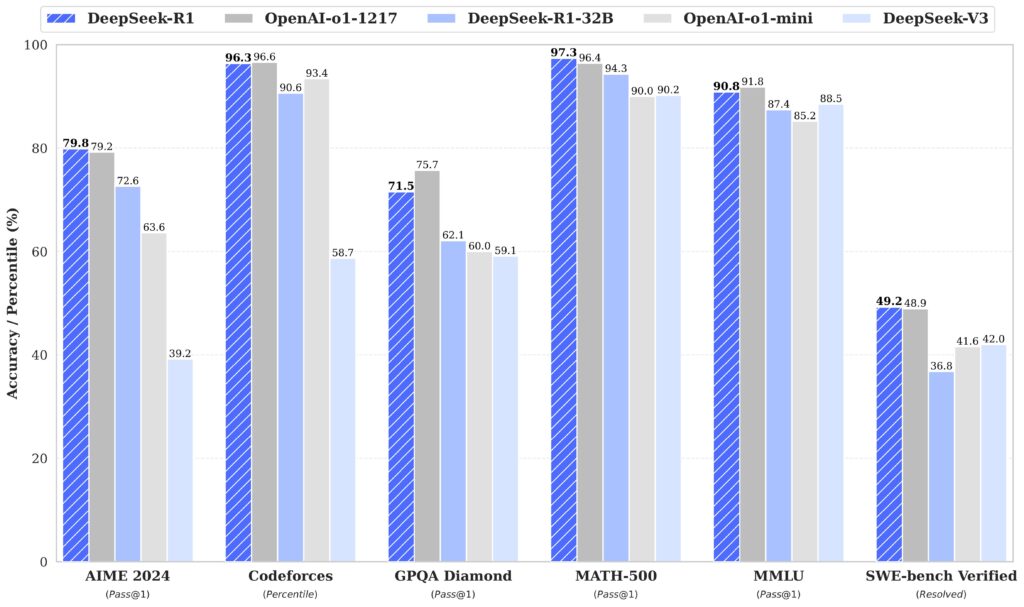
On Monday, Chinese AI lab DeepSeek released its new R1 model family under an open MIT license, with its largest version containing 671 billion parameters. The company claims the model performs at levels comparable to OpenAI's o1 simulated reasoning (SR) model on several math and coding benchmarks.
Alongside the release of the main DeepSeek-R1-Zero and DeepSeek-R1 models, DeepSeek published six smaller "DeepSeek-R1-Distill" versions ranging from 1.5 billion to 70 billion parameters. These distilled models are based on existing open source architectures like Qwen and Llama, trained using data generated from the full R1 model. The smallest version can run on a laptop, while the full model requires far more substantial computing resources.
The releases immediately caught the attention of the AI community because most existing open-weights models—which can often be run and fine-tuned on local hardware—have lagged behind proprietary models like OpenAI's o1 in so-called reasoning benchmarks. Having these capabilities available in an MIT-licensed model that anyone can study, modify, or use commercially potentially marks a shift in what's possible with publicly available AI models.
"They are SO much fun to run, watching them think is hilarious," independent AI researcher Simon Willison told Ars in a text message. Willison tested one of the smaller models and described his experience in a post on his blog: "Each response starts with a <think>...</think> pseudo-XML tag containing the chain of thought used to help generate the response," noting that even for simple prompts, the model produces extensive internal reasoning before output.
Simulated reasoning in action
The R1 model works differently from typical large language models (LLMs) by incorporating what people in the industry call an inference-time reasoning approach. They attempt to simulate a human-like chain of thought as the model works through a solution to the query. This class of what one might call "simulated reasoning" models, or SR models for short, emerged when OpenAI debuted its o1 model family in September 2024. OpenAI teased a major upgrade called "o3" in December.


The other thing is making it work and making it work even better than the original.
That's why the whole AI community has been buzzing about DeepSeek. Its training was estimated to cost a tiny fraction of what e.g. OpenAI has spent and not only that it's a lot cheaper to run.
You cannot underestimate the potential of 1.5 billion people.
this isn't just another open source LLM release. this is o1-level reasoning capabilities that you can run locally. that you can modify. that you can study. that's...
that's a very different world than the one we were in yesterday.
(and the fact that it's coming from china and it's MIT licensed? the geopolitical implications here are fascinating)
but the really wild part? those distilled models. we're talking about running reasoning models on consumer hardware. remember when everyone said this would be locked up in proprietary data centers forever?
something absolutely fundamental just shifted in the AI landscape. again, this is getting intense.
(also, wouldn't it be wild if deepseek renamed themselves to ClosedAI? 🤣)
2025 is going to be wiiiild